Contents · 11 sections
- How it all started
- Picking the prompt: why “LLM as the manager” failed
- The filtering funnel: not every dialogue is worth reviewing
- Designing the report and testing it
- Who went into the pilot, and why “Big Brother” didn’t happen
- The A/B test, an unexpected drop, and a lesson about human behavior
- Prompt chain: how we got the model to stop being lazy
- Fighting hallucinations: constraints in the prompt
- Pilot results
- Product evolution: from reports to the workplace, from the workplace to the simulator
- What I took away from this project
Several years ago we built an LLM tool that listens to sales calls, dissects them in detail, and tells managers how the conversation with the client could have gone better. First it was email reports, then an assistant embedded in the workplace, and eventually a full simulator where new hires train on synthetic clients. In this article I unpack what we did, what didn’t work on the first pass, and the takeaways I drew from it.
About this publication
This is a re-edition of my 2024 article from a corporate blog – reworked and expanded in 2026. It describes work done in 2023–2024: the first mentor pilot, the failed A/B test, the prompt chain. The historical context – why many of the decisions back then were derived from first principles – I’ll lay out in the first section.
How it all started
At the time I was working at a large financial company that also employed a huge number of client-facing managers. There were always new hires among them – full onboarding took about two months on average. Even seasoned employees made mistakes regularly: the product lineup is broad, client types vary, and you can’t standardize everything into scripts. So regular feedback from supervisors or senior colleagues was an important part of their workflow.
But listening to every call manually is impossible (we’re talking hundreds of thousands of conversations a day). By the time ChatGPT came out, our team had already been doing speech analytics for several years – we had our own near real-time, transcription with a few seconds of delay transcription, mature phrase-classification models, and access to an internal LLM. So the data was there, the tooling was there – all that remained was to assemble a product from it. 1+1 adds up to an idea: a tool that gives a manager feedback at the end of the day – not “you made 12 calls”, but “in this specific conversation you missed a chance to handle an objection, and here’s how it could have been done”.
Why many decisions below were derived from first principles
The project kicked off in mid-2023, around July – roughly seven months after ChatGPT’s public launch, and before LLM products with thousands of operational users started showing up en masse in large corporations. The first pilot went live toward the end of that year. There were almost no off-the-shelf patterns in the industry: no established prompt engineering in large teams, no infrastructure for multi-LLM systems, no proven ways to defend against hallucinations in production, no recognized approaches to roleplay simulators. Most of the decisions I describe below we derived from first principles – sometimes elegantly, sometimes through failure. And, in my view, this is what makes the text useful now: in hindsight you can see both what was born situationally and is no longer necessary today, and what carries over to new projects despite a dramatically changed model landscape.
Picking the prompt: why “LLM as the manager” failed
The first thing to check was how sensible the recommendations we could get from an LLM would be in the first place. To avoid drowning in scope, we narrowed the MVP down to one specific topic: handling client objections. If the model could pull that off, we’d build on top of it.
I prepared four approaches:
- Zero-shot prompt, version A – the model receives the dialogue and a general instruction: “evaluate how the objection was handled.”
- Zero-shot prompt, version B – the same idea, but with a more detailed frame for what to pay attention to.
- Dynamic one-shot – the prompt is filled with a specific client objection and an example of good handling.
- The role-reversal approach – the model plays the manager, and we feed it the client’s objection. Whatever it answers becomes our “reference”, which we then compare against the real manager’s response.
A simplified version of the fourth approach:
messages = [
{
"role": "system",
"content": (
"You are a bank manager. You are talking to a client. "
"Your task is to convince the client to accept the offer "
"and handle the objection correctly."
)
},
{"role": "user", "content": Client_phrase_1},
{"role": "assistant", "content": Manager_phrase_1},
# ... dialogue history
{"role": "user", "content": Client_phrase_with_objection},
]
I personally pinned the highest hopes on this approach – it felt elegant. In practice it performed worse than all the others.
Here’s what’s interesting: the reason, as I see it now, sits exactly where an off-the-shelf LLM has its biggest blind spot. RLHF-trained models are systematically too agreeable. When you ask them to play the manager talking down a client, they produce a textbook-looking answer, but that answer doesn’t account for the actual dynamics of the conversation – the way a live client interrupts, drifts off topic, refuses to hear arguments. Comparing a live manager’s line against such a “reference” is like rating a boxer by how he hits a punching bag: there’s no resistance context.
In the end we settled on the dynamic one-shot approach: for each dialogue the prompt was assembled dynamically with a specific objection slotted in and a request to assess whether the manager’s response was correct. Not the prettiest variant, but the most stable and predictable one.
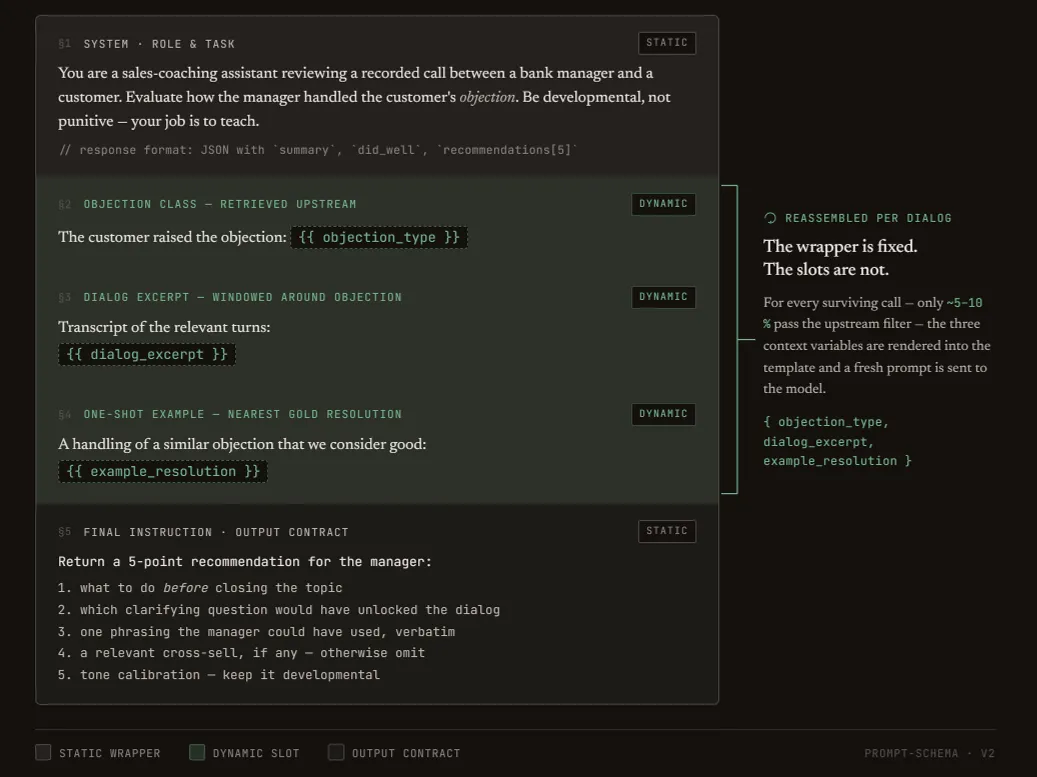
The filtering funnel: not every dialogue is worth reviewing
To slot “a specific objection” into the prompt, you first have to find one. We could have asked the same LLM to first classify the dialogue and then review it – but that would be expensive and pointless (far from every dialogue contains an objection worth reviewing).
So we built a filtering funnel on top of classical phrase classifiers – far cheaper than an LLM, running in milliseconds rather than seconds. The funnel ranked dialogues by several criteria:
- presence of a client objection,
- an attempt by the manager to address that objection,
- whether the manager asked an opening question about the client’s business,
- dialogue length,
- metadata (product type, client segment, etc.).
After filtering, no more than 5–10% of all dialogues made it through to the LLM – the ones whose analysis would actually give the manager something new.
This pattern – “cheap pre-filter + expensive model only on what passed through” – I still use in every LLM product I build. It saves orders of magnitude more money than any inference optimization. On top of that, it cures a second problem: information overload. A manager physically can’t read fifty recommendations a day. Give him three but precise ones – and he’ll apply them. Give him fifty, and he won’t read any.
Designing the report and testing it
Since this was an MVP, we deliberately skipped integration with CRM and the speech-analytics portal (all of which means inevitable multi-week approval cycles). Instead we picked the cheapest delivery channel – an email report to the manager’s supervisor at the end of each working day.
The logic was: if the recommendations are useful, the supervisor will work through them with the manager at the daily stand-up. If they’re useless – he’ll be the first to notice and send us feedback.
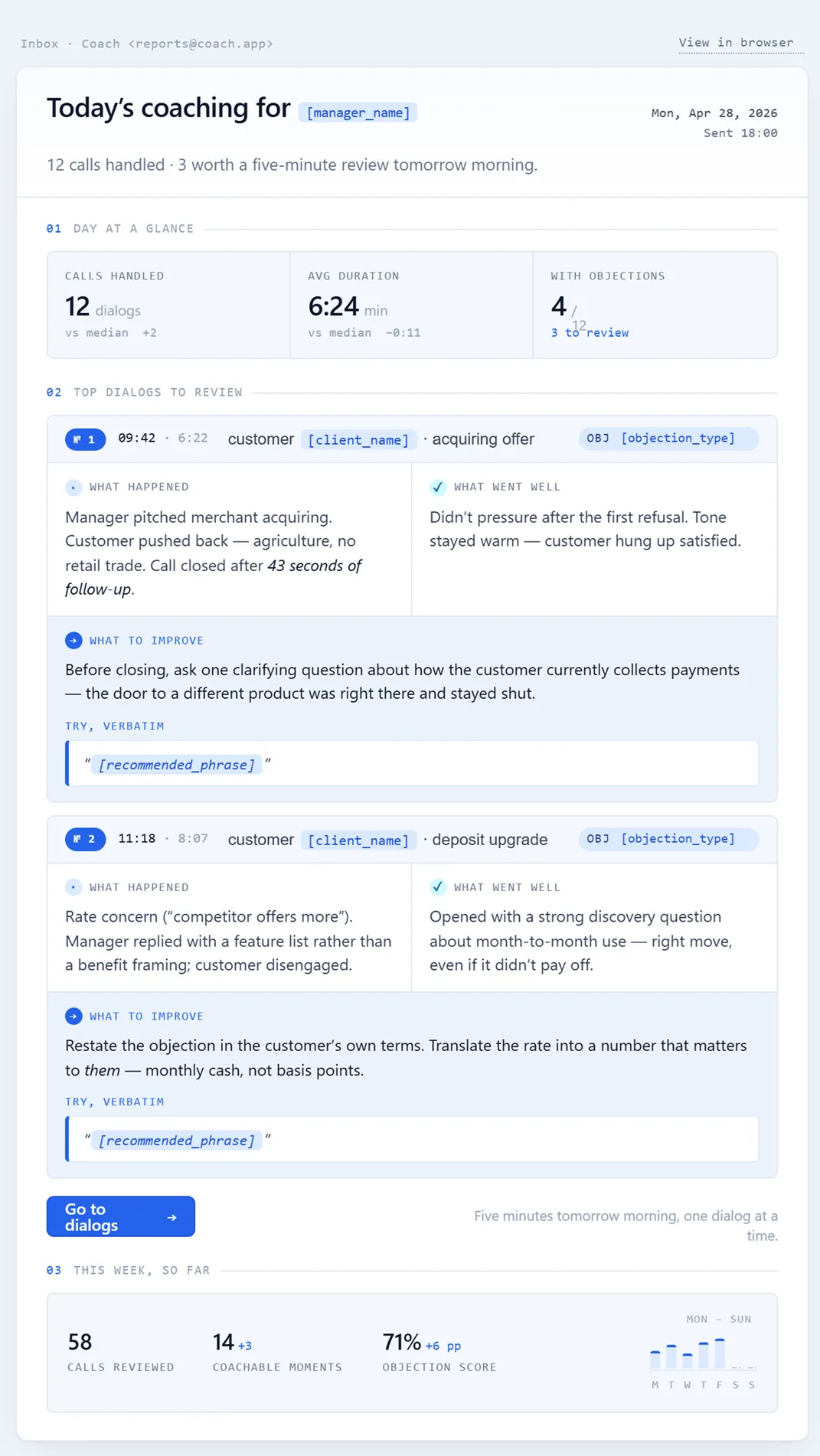
Who went into the pilot, and why “Big Brother” didn’t happen
This is the question I get asked most about this project. In short: participation was not voluntary for managers. There were reasons.
Pilot structure. We took four sectors in full and placed them in the treatment group. Not half a sector – the whole thing. The control was a “virtual sector” assembled from managers in other departments not involved in the pilot, matched on characteristics to align with the treatment group.
Why that way. If we’d taken half the managers in a sector into the pilot and left the other half without recommendations, we’d have gotten two effects, both confounding. If a supervisor receives reports on half the team while the other half sits at the next desk waiting for the same, either feedback starts spilling across desks, or the supervisor has to artificially hold it back. Neither looks like a clean experiment. So the unit of randomization was the sector, not the manager: that reduces the test’s statistical power, but gives a clean signal.
We didn’t collect the managers’ consent. This is probably the spot where an outside reader’s eyebrow goes up the highest – so let me explain it straight. Before launch we walked the managers and their supervisors through what we were doing and why, that the tool was developmental rather than punitive, and how exactly it could help them. No pushback. Not because the managers were intimidated, but because pilots like this run constantly in large operational units, and for them it wasn’t a unique event but just the next experiment in a long line.
Call recording and automated call analysis had existed in this segment long before us. Managers were already working in an environment where their conversations are transcribed, classified, and end up in reports. Our tool didn’t add new visibility to this picture – it added a new type of feedback on top of what was already there. The novelty wasn’t the surveillance; it was that the feedback became targeted.
There’s a general transfer here, I think. When people assess the ethics of an AI tool, they almost always compare it against a world in which that tool doesn’t exist. In practice it’s more appropriate to compare it against a world in which whatever existed before is still running – legacy analytics, manual reviews, the occasional supervisor listening in. Against that backdrop a good AI tool almost always reduces the arbitrariness of control rather than increasing it, because it more often operates by clear rules, and human oversight doesn’t.
How we validated the pilot's reception (and what we didn't do)
We collected feedback during the pilot through tight working contact with managers and supervisors. Weekly syncs, dedicated sessions, walking through negative reactions. The bulk of negative comments wasn’t about the fact of being evaluated, but about model errors themselves – when the LLM hallucinated, when the classifier fired in the wrong direction, when a recommendation was inappropriate. That’s normal negative feedback; you fix it iteratively. Positive comments were noticeably more frequent; some managers who went through the pilot then actively waited for the full launch.
What we didn’t do – we didn’t run formal psychological measurements. No questionnaires, no stress scales, no before/after measurements of emotional state. The decision rested on the assumption that feedback and regular syncs were enough, and given our scale and context, I think that was reasonable. In hindsight – I’d note for myself that for projects where AI enters an environment without an established culture of observation for the first time, formal measurements are worth building in from the start. We didn’t have that problem; in a different environment we might have.
Another deliberate detail – how the recommendations are worded. We intentionally kept the report away from the “here’s where the manager messed up” tone. Even where, by our internal metrics, a manager was objectively trailing his peers, that didn’t get translated into the recommendation text. The tone was motivating, the feedback was about what could be improved, not about what had been bad. We specifically tuned the prompt for this behavior. Today every model talks to you like that by default. But at the start of the pilot, if we hadn’t hard-wired this behavior in, the LLM wrote in a clinical, cold register, and some managers might have read it as an accusation even where there were no actual complaints. Hence a narrow but transferable takeaway: a developmental AI tool needs to be explicitly told in the prompt that it’s developmental, not evaluative.
The A/B test, an unexpected drop, and a lesson about human behavior
We launched the pilot knowing that hallucinations weren’t going anywhere and that some fraction of recommendations would be wrong. That’s why the reports went to supervisors – they filtered out the junk and collected feedback.
A month in, we looked at the A/B-test results and saw conversion drop in the treatment group. That is, managers who received our recommendations were selling worse than those who didn’t. Not what we were expecting.
We figured out fairly quickly what had happened – and the nature of the problem turned out to be telling. The supervisors got fixated on the report itself rather than on applying it. They actively collected feedback on the wording, argued about which blocks needed improving, discussed what would be more useful to see. All of that was useful for us as developers, but it pulled them away from the pilot’s actual job: each morning, take one recommendation from the report and walk through it with the specific manager before his calls.
The paradox was that supervisors had been running coaching sessions before this – that’s part of their regular job. What we introduced wasn’t “review sessions appeared”, it was “now there are LLM recommendations to use in those sessions”.
Looking back, I get it now: an insight on its own changes nothing. Behavior only changes when something is wired into the workflow. We relaunched the pilot, adding:
- a clear cadence: every morning the supervisor spends 15 minutes walking through one case from the report with the manager;
- a simpler report format (there used to be too many blocks, and supervisors drowned in choosing what to review);
- a drop in frequency from daily to weekly – the weekly cut turned out to be more informative and didn’t trigger “report fatigue”.
After the relaunch, the numbers went up.
Prompt chain: how we got the model to stop being lazy
The second big problem – the model kept ignoring parts of the instruction and producing shallow recommendations. Things like “the manager could have handled the objection better by asking clarifying questions.” Thanks, Captain Obvious, “really helpful.”
The fix was a prompt chain – we split the “analyze the dialogue” task into three sequential LLM calls, with plain glue code between them:
- Detailed dialogue analysis. What happened, what the objection was, which product, how the manager tried to address it.
- Summary assessment. What in that handling worked and what didn’t – point by point, based on the analysis from step one.
- Corrective feedback. Concrete alternative phrasings and one relevant upsell.
The final assembly of the readable report isn’t a separate prompt anymore, just plain code stitching the results together and formatting them for HTML/markdown. No LLM in this step – cheaper and more stable that way.
We measured the effect on a test basket of hand-labeled dialogues: the share of recommendations that reviewers tagged as relevant and actionable went from 54% to 78% versus the monolithic prompt. And this isn’t accidental – LLMs handle tasks broken into narrow steps better, because at each step the model has fewer “temptations” to cut corners. The broader the task in a single prompt, the higher the chance the model averages out the response and skips details. It’s still often the case today, and back then it was the only way to make this work properly.
Fighting hallucinations: constraints in the prompt
A separate surprise was how often the model confidently recommended things it shouldn’t. For instance, suggesting the manager “work out a custom rate with the supervisor” (the company has no process for custom rates in this segment), or, my favorite hallucination, the LLM suggested recommending the client switch to a competitor.
From the LLM’s point of view these are picture-perfect, customer-centric recommendations. So we had to add negative constraints to the prompt:
- don’t recommend custom terms;
- don’t offer specialist consultations outside the standard process;
- don’t mention products outside the list approved by the business;
- and so on.
By the way, this is a general pattern I’ve started applying everywhere: in any LLM product there’s always a “shadow requirement” – a list of things the model is not supposed to do, and it needs to be spelled out explicitly in the instruction. Counting on the model to figure it out from context doesn’t work. Today’s LLMs do this much better, but on complex cases you still often have to play it safe.
Pilot results
In short:
- Sale conversion in the treatment group rose by roughly +19.7% against the control – this was after we relaunched the workflow and simplified the report format.
- The effect held strongest where objection handling had been most structured to begin with: product lines with mature methodologies for working with doubts. On those lines the lift was several times the average; on lines with less formalized practice – closer to noise.
- Beyond objection-handling quality, we added emotional dialogue scoring and how close the manager’s lines were to recommended scripts – this let supervisors see patterns rather than isolated cases.
- Report frequency dropped from daily to weekly – people only have so much attention to spend.
I can’t share more detailed numbers by segment, specific products, or absolute conversion values – that part is under NDA. So everything below describes the shape of the effect and the decisions, not the specific figures.
Product evolution: from reports to the workplace, from the workplace to the simulator
The most interesting part started after the pilot. An arc of three stages, on each of which what changed wasn’t so much the model’s quality as when exactly the manager received the feedback.
Stage 1. Email reports – everything I described above. Lagging feedback: the manager learns about his mistakes 6–24 hours after the call, when the conversation’s context has already faded and the specific client is lost.
Stage 2. Embedded in the workplace. The hints moved into the interface the manager actually uses to handle calls: recommendations showed up right in the client card after the dialogue, while the conversation was still fresh in his head. On top of that, real-time hints appeared during the call itself – short signals like “client asked about fees, clarify the type of operations.” The feedback loop shrank from a day to minutes, and behavior shifted: managers started coming back to the recommendations between calls, instead of ignoring an inbox buried in tasks.
Stage 3. Simulator. For new hires the main blocker isn’t “knowing the scripts” but lack of practice – teaching sales from a PDF is the same as teaching swimming from a book. So we built a training mode where the LLM plays the client and the manager trains on his own failed conversations, with no consequences for real clients. That’s a separate engineering story with its own long price tag: getting a base LLM to play an uncooperative client without breaking character turned out to cost more than building the mentor. Details – in the second article of the series.
What came out is an arc: analyzing real dialogues → embedded hints at the moment of work → low-stakes practice on synthetic dialogues. From lagging feedback to real-time feedback to proactive practice. In my view, that’s exactly how a mature AI layer on top of an operational process should evolve.
What I took away from this project
Five takeaways I’ve been carrying into every LLM product since:
- “Elegant” prompts are often worse than boring ones. The role-reversal approach felt graceful; dynamic one-shot felt blunt. The blunt one won.
- The LLM isn’t the most expensive part of the pipeline if you filter properly. A funnel of cheap classifiers in front of the LLM saves orders of magnitude.
- Model quality loses to delivery channel. You can build a perfect model, but if it reaches the user via email – it won’t work. The same model wired into the workplace – will.
- Decomposing the prompt into steps is almost always a win. One big prompt is almost always worse than three small ones.
- LLMs have “shadow behavior” you need to explicitly forbid. Otherwise it will confidently promise clients things that can’t be.
And probably the most important meta-lesson: AI tools embedded in workflows live on their own development curve. First – reports. Then comes embedding at the moment of action, and only after that – training before the action. If you launch straight into stage three, you won’t have the data or the pattern understanding. If you get stuck at stage one – nobody will use it.
Appendix: an example of a recommendation the system produces
For anyone curious about what the model’s output looks like – an example (the dialogue is abstract, without specifics of any particular bank).
Dialogue analysis:
The manager calls a client to pitch a merchant acquiring service. The client says he has no retail business (his sphere is agriculture) and objects to the offer. The manager doesn’t try to dig into the details, accepts the objection, and ends the call.
Objection-handling assessment:
Positives: the manager doesn’t pressure the client and thanks him for the information – this builds a positive impression.
Negatives: the manager didn’t ask a single clarifying question about how the client handles payments with his buyers, and offered no alternative products. In effect, the conversation closed on the first “no”.
Recommendations:
- Before closing the topic – ask a clarifying question about current payment methods: “I understand merchant acquiring isn’t a fit for your industry. How are payments with your buyers organized right now?”
- Based on the answer, pick a relevant product (e.g., a tool for accepting non-cash payments from corporate clients).
- Frame the benefit in the client’s terms, not the bank’s (“saves time on reconciliation”, not “a modern solution”).
- If the decision isn’t immediate – offer to send materials and agree on a convenient time to follow up.
A retrospective on our LLM mentor for sales managers – a 2023–2024 project. Picking the prompt through failures, designing a pilot without a 'Big Brother' effect, an A/B test that went the wrong way, and a three-step prompt chain instead of one. This is the first article in the series – an overview: the journey, the failures, and the five takeaways I've been carrying into every LLM product since.
To train managers you need a virtual client who resists and says no. An off-the-shelf LLM fails hardest exactly here – RLHF made it agreeable. I unpack how an uncooperative interlocutor is assembled out of a friendly assistant: role layers, different temperatures for the client and the validator, a ban on cheap excuses, the director's note 'you don't know this' – and why the client's reply gets no quality judge, only a check for whether the conversation is over.